Cursor Composer 2.5 Matches Opus 4.7 at 1/10th the Price
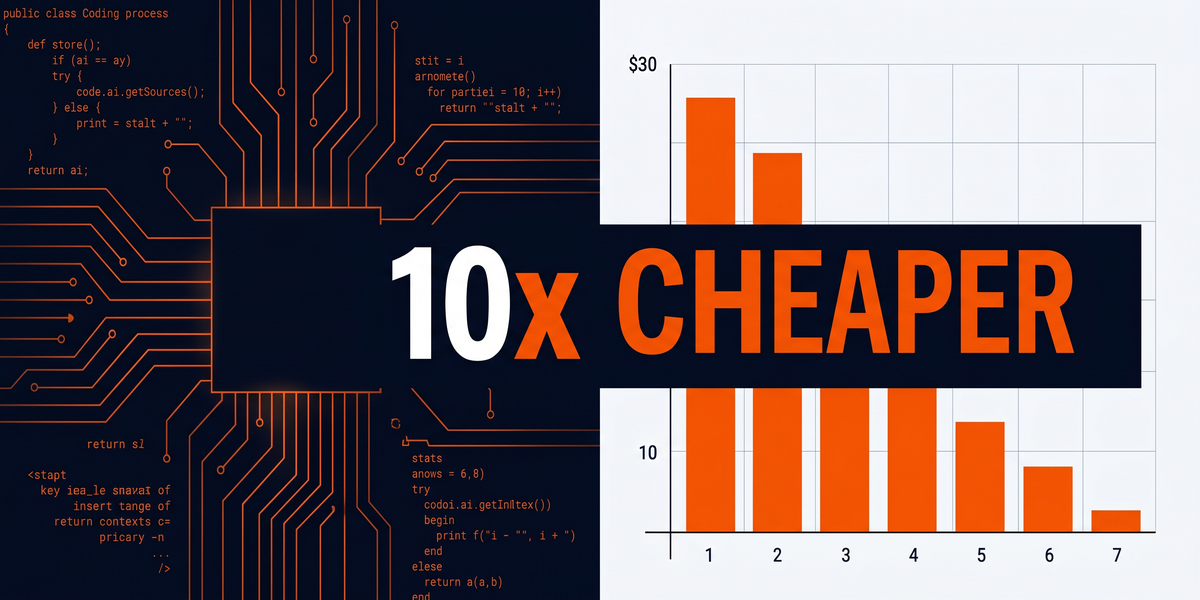
Key Takeaways: - Composer 2.5 hit 79.8% on SWE-Bench Multilingual versus Opus 4.7's 80.5%. A 0.7-point gap, not a gulf - CursorBench v3.1 scores actually edge past Opus: 63.2% vs 61.6% - Input pricing is $0.50/M versus $15/M for Opus. Roughly 30x cheaper for equivalent benchmark performance - Cursor reports under $1 average cost per task on CursorBench; frontier models run $3-11/task - Cursor is partnering with SpaceXAI to train a new model from scratch on Colossus 2 (1M H100-equivalents)
---
That benchmark number that should change your next invoice
Cursor Composer 2.5 hit 79.8% on SWE-Bench Multilingual. Opus 4.7 scored 80.5%.
0.7 points. That's it.
CursorBench v3.1 tells a different story though.
Composer 2.5 actually edges past Opus there: 63.2% versus 61.6%. Terminal-Bench 2.0? Dead even at 69.3% to 69.4%.
These aren't synthetic tasks nobody runs.
These are the tasks devs run all day long.
So. If you're paying $15/M input tokens for Opus 4.7, you kinda gotta ask what you're actually getting.
For most coding work. Scaffolding, tests, refactors, bug fixes. That 0.7-point gap? Doesn't show up. The $14.50/M difference? Shows up in your bill every single month.
Oh, and Elon Musk quote-tweeted the launch ("Try it out! Partially trained on Colossus 2") and pulled 8.9M views. Hacker News exploded with 100+ comments.
The coding tool world definitely noticed.
---
What $0.50/M actually means for a dev team
Let's do quick math. Five-person dev team running coding agents eight hours a day. Not unusual if you're automating PR reviews, test generation, docs.
Might burn through 50-100M tokens a week per developer.
250-500M tokens a week across the team.
At $0.50/M tokens: $125-$250/week.
At $15/M tokens: $3,750-$7,500/week.
For the same benchmark performance.
That's the difference between AI-assisted development being a real line item in your budget and a rounding error.
Here's the thing. Most small shops, indie devs, they're running frontier models and just absorbing the cost because "that's what professionals use." Composer 2.5 breaks that assumption cold.
Cursor's own numbers show under $1 average cost per task on CursorBench.
Frontier models? $3-11 per task for similar results.
If your workflow involves hundreds of agentic coding operations a day.
And if you're reading this, it probably does. The economics shift hard. Real hard.
---
The story the benchmark coverage is missing
Cursor built Composer 2.5 on Moonshot AI's open-source Kimi K2.5 checkpoint. Same base as Composer 2. But they ran 25x more synthetic tasks during training. And they developed a new reinforcement learning technique called "targeted textual feedback" that injects localized hints during training instead of relying on overall reward scores.
That's the key bit nobody's talking about.
It's not just more compute.
It's a smarter training signal. That's what closes the gap with frontier models on real-world coding tasks.
Now here's where it gets interesting. Cursor's working with SpaceXAI on a significantly larger model trained from scratch. Ten times more compute. On Colossus 2.
A million H100-equivalents.
They're not fine-tuning someone else's base model anymore.
They're building foundation models.
If that lands. And that's a big if, honestly. The coding agent war has a new full-stack player. $2B annualized revenue. $50B valuation trajectory. Fastest-growing category in developer tools per The Next Web.
Anthropic and OpenAI aren't just fighting each other anymore.
They're fighting a well-funded, fast-moving player with direct access to one of the largest compute clusters on earth.
Side note: their docs are kind of a mess. But that's a other problem.
---
Should you switch? Here's my honest take
I run coding agents for client work every day.
Evaluating Composer 2.5 as my default model right now. Not since it's perfect. The SWE-Bench gap is real, Opus 4.7 still leads on some tasks. But the price-to-performance ratio for everyday work? Deniable.
For specialized tasks that need frontier-level reasoning — complex architecture decisions, novel algorithm design, high-stakes security work — I'd still reach for Opus 4.7. The marginal benchmark difference matters there.
But for the 80% of coding tasks that are well-defined, repetitive, and don't need the most advanced reasoning? Composer 2.5 at $0.50/M is the obvious choice.
The cost savings compound.
Performance is there.
If your team's still paying frontier prices for routine coding tasks, you're burning margin that could fund another hire, another product, or just better tooling.
The benchmark case is closed.
The economic case is overwhelming.
Try Composer 2.5 on your next task. See if the output matches what you're paying 30x more for. If it does. And in my testing, it usually does. The choice is obvious.
---
Sources: - Hacker News discussion (100+ comments) - StartupFortune: Cursor Makes Composer 2.5 a Cheaper Rival - Digg/X coverage with Musk quote tweet - Apidog benchmark comparison table - LushBinary pricing tier breakdown - WhatLLM May 2026 model tracker
Comments ()