GPT-5.5 Codex Reasoning Tokens Pile Up at 516
Key Takeaways
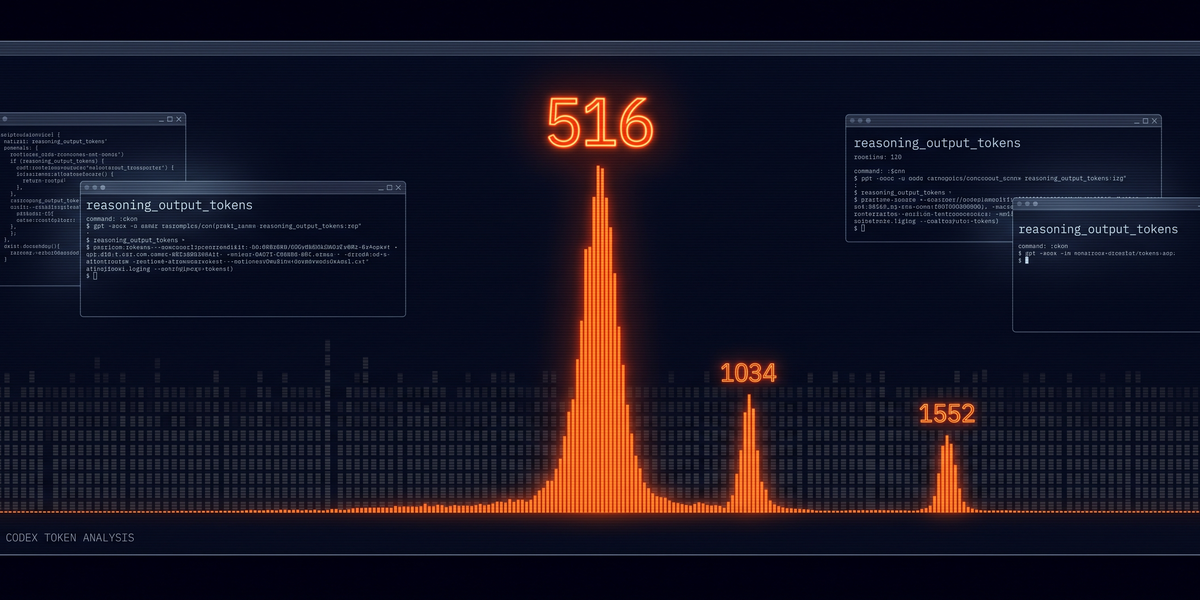
- A significant number of responses hit exactly 516 reasoning tokens. - Secondary clusters show up at 1034 and 1552 tokens, roughly 518 apart each time. Those spikes line up with wrong answers on harder coding tasks. - The researcher who published this calls it a telemetry anomaly, not a proven model bug. Nobody's confirmed hidden chain-of-thought truncation. But nobody's ruled it out either.
Something weird is happening with GPT-5.5 Codex. Its internal reasoning keeps stopping at the same exact number — 516 tokens. Over and over.
And the developers who depend on this model for real production work have started paying attention.
A GitHub issue dug through a significant number of response-level token records.
Found many events parked at exactly 516 reasoning_output_tokens. GPT-5.5 generated a significant portion of those despite carrying a smaller share of total sample volume. The issue author is careful here. They're not claiming OpenAI built a secret reasoning cap. They're saying the numbers cluster in a way that deserves explanation and doesn't have one yet.
Here's what that means if Codex runs through your production stack.
And what you should do about it.
What the Numbers Actually Tell Us
The source material is a public GitHub issue on the openai/codex repository.
A significant number of token records. Many of them land on 516 exactly. And GPT-5.5 owns a significant portion of that bucket while representing a smaller share of overall traffic.
That's the whole signal right there.
Think about it probabilistically. If token distributions were random, a model handling a smaller share of your requests shouldn't fill a large portion of any specific bin. That's not how noise works. A Hacker News thread that followed the issue spotted two more clusters — 1034 and 1552. Each separated by about 518 tokens. Same model. Same pattern.
Then the implications get uncomfortable fast. That HN thread connects these fixed-boundary responses to task failures on complex prompts. One person described feeding GPT-5.5 a logic puzzle. Watched it spend exactly 516 tokens reasoning. Got a confidently wrong answer back. A Reddit thread in r/codex echoed this.
Multiple users saying the degradation isn't isolated, with one noting quality "jumps down almost daily."
But hold on.
The GitHub issue author explicitly warns against jumping to conclusions. They call this a telemetry anomaly. Their words, not mine. The data doesn't prove hidden chain-of-thought truncation.
That caveat is doing heavy lifting. The distance between "OpenAI secretly caps reasoning" and "something in routing or budget logic produces odd clusters" is massive.
The evidence we have points firmly at the second interpretation.
Your Codex Pipeline May Already Be Bleeding
Solo dev or small shop running GPT-5.5 Codex for client deliverables?
This hits you directly.
You're burning tokens on reasoning that might slam into an invisible ceiling before the model finishes its thought process. The output looks done. Reads like a completed response. Ships like one too.
Then the bugs show up in production.
Or your client's users find them.
Honestly, silent quality drops are scarier than crashes. A crash forces action. You retry, you escalate, you notice. A response that burns exactly 516 reasoning tokens and returns a plausible-but-wrong answer? That sails through review. It looks finished. Nobody flags it until something breaks downstream.
The GitHub issue author makes a sharper observation than just "check your token counts." They point out that abrupt model-specific boundaries in reasoning output can expose routing problems, budget artifacts, instrumentation quirks.
All before those issues register in your aggregate success metrics. For small operators, that's free early-warning telemetry if you bother to collect it.
This isn't theoretical hand-wringing either.
GitHub, HN, Reddit, X. The evidence converges from every direction. GPT-5.5 produces fixed-boundary clustering in reasoning tokens. Those clusters correlate with task failures. The issue author stresses this remains community-reported evidence with zero official root-cause confirmation. OpenAI hasn't commented publicly. You're on your own until they do.
Building a Token-Count Early Warning System
The GitHub issue includes a specific operational recommendation worth copying. Track your reasoning token distributions as a reliability signal.
The reasoning is dead simple.
Sudden model-specific boundaries in token counts flag routing, budget, or instrumentation problems before they crater your pass rates. You see the pattern in telemetry. You catch it before it reaches your codebase.
Concretely for a small team: log reasoning_output_tokens on every GPT-5.5 Codex response. Then watch for spikes at 516, 1034, 1552. When you spot a cluster, pull those responses. Compare their task success rate against responses with normal token distributions. You're hunting the correlation the community already described — fixed token counts paired with wrong answers.
Let me be clear about what this isn't.
This isn't about proving OpenAI built a hidden reasoning cutoff.
The issue author says the data doesn't support that claim. This is operational awareness. Knowing when to retry. When to swap models. When to pull a response aside for manual review before it touches a client repo.
If paid client work flows through GPT-5.5 Codex, you need this visibility.
Trusting a model that short-circuits at fixed intervals isn't a strategy. It's a gamble with someone else's money.
The Bigger Picture for Small Teams
Mid-2026. AI coding tools are getting real scrutiny from people who ship with them daily.
A GitHub issue about reasoning-token clustering, ricocheting across HN, Reddit, and X. That tells you builders are hitting the actual edges of what these models do reliably. Those edges don't show up in the launch blog posts. They show up in your bug tracker at 2am.
The evidence points in one direction. GPT-5.5 clusters reasoning output at 516, 1034, and 1552 tokens. Those clustered responses tie to task failures. Root cause? Unknown. The issue author calls it a telemetry anomaly. No hidden chain-of-thought cutoff proven.
tbh, if you're running lean, your move is obvious. Start logging reasoning_output_tokens today. Not next sprint. Today. Track failure rates against token counts. Stop assuming that a response without an error message actually succeeded.
When the community surfaces a pattern like this, test it against your own workload. Don't dismiss it. Don't panic either. The 516-token cluster is a signal worth watching. Not a verdict on GPT-5.5's quality. Handle it that way and your pipeline gets tougher. Ignore it and you'll keep debugging code that should've landed clean the first time.
Sources
- GitHub issue: openai/codex #19464 - Hacker News discussion - LetsDataScience analysis - Reddit r/codex thread - X post by @bdsqlsz - OpenAI Reasoning models documentation
Comments ()