Your iPhone Is Now a Private AI Server
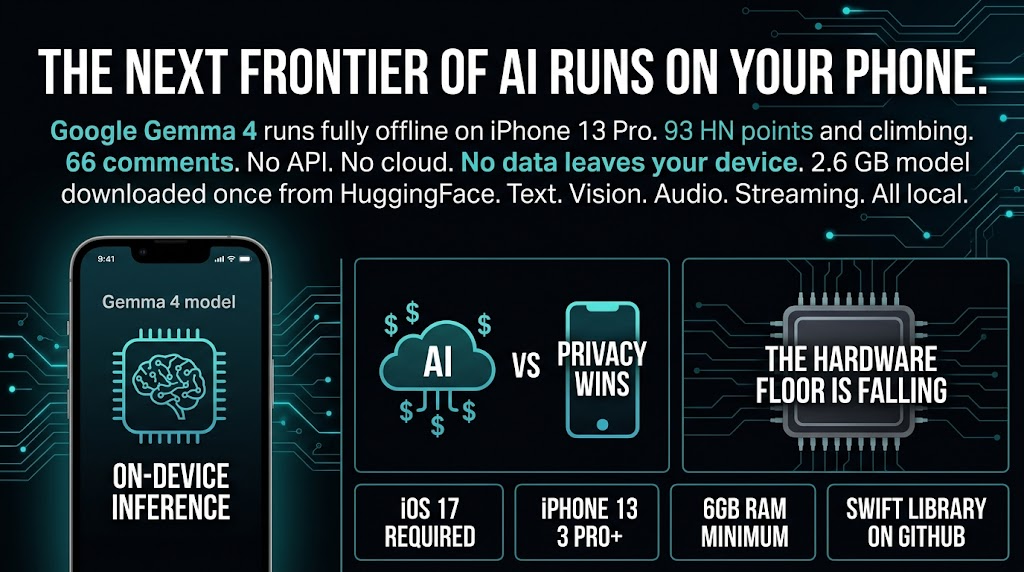
This story went from 14 points to 93 in a few hours on HN. A developer posted working code that runs Google's Gemma 4 model directly on an iPhone 13 Pro. No cloud. No API calls. No internet required once the model loads. Sixty-six people commented in hours. This is the story people are actually paying attention to today.
Your iPhone is now a private AI server. Not someday. Today.
Here is the thing I keep coming back to as an agency operator.
For two years I have been telling clients that their AI workflow data is safe because we use good providers with solid compliance certifications. That is the version of the truth I can sell. But it is still a version of the truth. Every API call gets logged on someone else's server. Every query sits in someone else's training pipeline unless you pay for enterprise contracts that actually opt you out. The data does not disappear because you wish it would.
This changes that calculus.
The package is called LiteRTLM-Swift. It wraps Google's official LiteRT-LM C API in an async/await Swift interface. Text generation, vision, audio, streaming output. The Gemma 4 E2B model is about 2.6 GB. You download it once from HuggingFace. Then it runs completely offline. First launch takes five to ten seconds to load into memory. After that, no internet is needed at all.
It gets better. Or worse, depending on how you look at it.
No API costs. None. Once the model is on the device, inference is free. No per-token billing. No rate limits. No latency spikes when OpenAI has a bad day and your production app starts timing out. No dependency on internet connectivity. Field workers, travelers, anyone in a sensitive environment where data cannot leave the premises.
This is what the privacy-first AI argument has been pointing toward. Not policies and compliance certificates. Actual architecture where the data never exists in a place you do not control.
But wait. Here is the honest limitation.
You need an iPhone 13 Pro or newer with at least 6 GB of free RAM. iOS 17. Xcode 16. The increased-memory-limit entitlement has to be set manually. This is a developer setup, not a consumer app. The first launch takes longer than you want. The model sits in memory and iOS can evict it under pressure.
That hardware floor is a real constraint today. The majority of iPhones in active use do not meet the minimum spec. Your clients are probably not running this yet.
Here is the part that keeps me up at night though.
Hardware floors do not stay where they are. Two years ago, running a capable AI model on a phone was theoretical. Today it is a GitHub repo with 93 points on HN. The iPhone 13 Pro is three years old. The minimum spec in 2028 will be laughably overpowered by today's flagship standards.
The question is not whether this becomes normal. It is whether you will be ready when it does.
If you are building AI features into client deliverables today, you are probably architecture decisions that assume cloud-only inference. The on-device reality is arriving faster than most roadmaps account for. Free, offline, private inference changes how you price AI features. It changes what you can promise in compliance reviews. It changes whether you can offer functionality that works in air-gapped environments.
This is not a future concern. It is a present engineering constraint that is loosening fast.
Here is what to do about it.
Go to the GitHub repo. Read the setup instructions. If you have an iPhone 13 Pro or newer, try running the model today. Not to ship it to clients. To understand what it actually feels like to run inference that costs nothing and leaves no trace. That experience will change how you think about every cloud AI feature you are currently building.
The iPhone in your pocket is more powerful than a server room was five years ago. That is not marketing copy. That is the spec sheet. Figure out what you can do with it before your competitors do.
Sources: - LiteRTLM-Swift GitHub Repository - Hacker News Discussion
Comments ()